A Technical Deep Dive Into AIOZ Network’s AI Smart Routing Delivery

This technical article will take a deep dive into the AIOZ Network’s use of smart routing and how it helps bolster our efforts to create a truly decentralized content distribution network. These are just some of the problems the AIOZ team has been solving over time.
With the introduction of Software-Defined Networking (SDN), Network Function Virtualization (NFV), and 5th-generation wireless technologies, networks throughout the world have recently undergone substantial reorganization and transformation (5G).
The dominance of conventional ossified architectures is eroded by emerging networking paradigms, lowering reliance on proprietary hardware. However, the associated increases in network flexibility and scalability pose new problems for network administration.
Because network complexity is rising all the time, effective network control is becoming increasingly challenging. Current control techniques, in particular, rely heavily on manual procedures, which have inadequate scalability and resilience for the management of complex systems.
As a result, there is an urgent need for more effective techniques for tackling networking issues.
AI-Driven Traffic Routing
With the remarkable success of machine learning, Artificial Intelligence and Machine Learning (AI&ML) applications in networking have gained much attention.
When compared to painstakingly developed tactics, AI&ML approaches offer significant benefits in networking systems. AI&ML provides a generic model and consistent learning approach for diverse network settings without predefined procedures.
Furthermore, such strategies can handle complicated issues and high-dimensional circumstances well. Aside from the enormous benefits of AI&ML for networking, creating a novel network is also fertile ground for AI&ML implementation.
The growing trend of using AI&ML in networking is driven by job requirements (increasing network complexity and increasingly demanding QoS/QoE needs) and technical advancements (network monitoring technologies and big data analysis techniques).
Centralized and decentralized routing using AI-powered reinforcement learning has recently been stated to be applied in Smart Routing. However, both of them remain problems during AI learning.
To improve our network routing with the fanciest technique, we use a three-layer logical functionality design. This design can be understood as a combination between both groups above of approaches, which leverage the advantages of each approaches to cover the other’s weaknesses.
Three-tier logical design: The closed-loop control paradigm
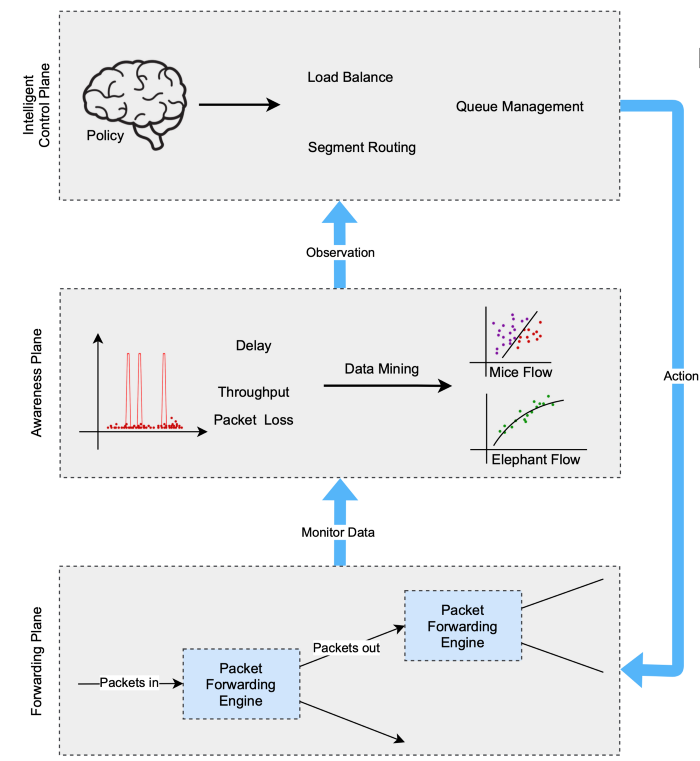
Figure 1: The closed-loop control paradigm
The advancing plane, the awareness plane, and the intelligent control plane are the three layers of the paradigm, as shown in Figure 1.
In a distributed network, the forwarding plane moves data packets from one interface to the next. Its operating logic is reliant on the control plane’s forwarding table and configuration instructions.
The awareness plane’s job is to keep track of the network’s state and report back to the control plane. Network awareness and monitoring are required for ML-based control and optimization.
As a result, we abstract this new layer, which we call the awareness plane, to gather and process monitoring data (for tasks like network device monitoring and network traffic identification) to deliver network status information.
The intelligent control plane is in charge of supplying forwarding plane control choices. In this aircraft, AI&ML-based algorithms are used to convert current and historical operating data into control rules.
The combination of these three abstract planes creates a closed-loop architecture for AI&ML deployment in networking. The advancing plane serves as the “subject of action,” the awareness plane serves as the “subject of observation,” and the intelligent control plane serves as the “subject of learning/judgment,” analogous to the human learning process.
An AI&ML agent may constantly learn and optimize network control and management methods based on these three planes for closed-loop control by interacting with the underlying network.
Hybrid architecture
A hybrid AI-driven control architecture illustrated in Figure 2 is specially designed to fit our system. It combines a “network mind” (centralized intelligence) with “AI routers” (distributed intelligence) to support various network services.
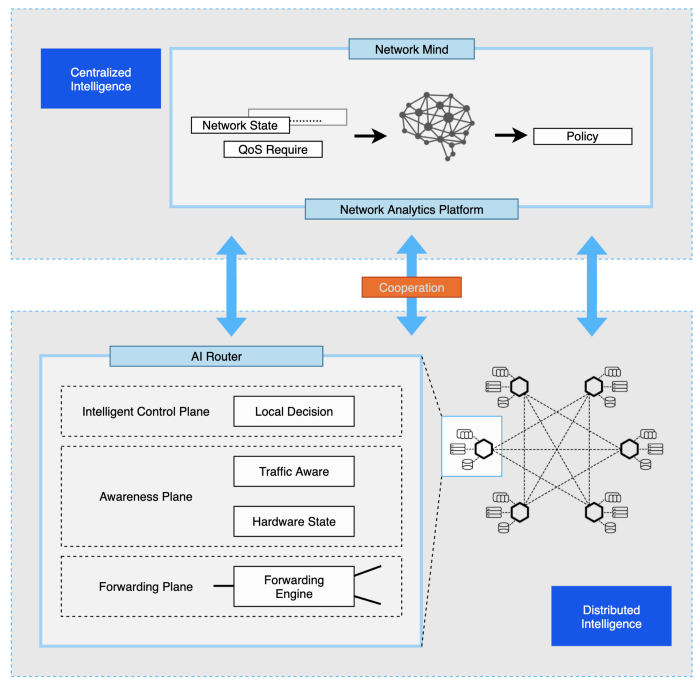
Figure 2: The hybrid architecture
Network Mind
Architecture
As depicted in Figure 3, the network mind is in charge of centralized intelligent traffic control and optimization. The network mind uses an upload link to obtain the fine-grained network status and a download link to issue actions.
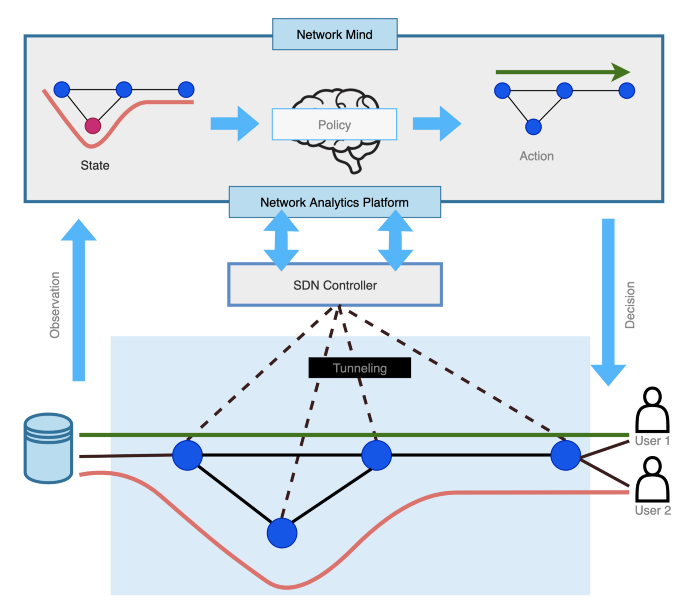
Figure 3: The centralized intelligent control scheme
The upload connection uses a network monitoring protocol like INT, Kafka, or IPFIX; the download link uses a standard southbound interface like OpenFlow or P4 to allow efficient network control.
The upload and download links provide an interaction structure that gives the network mind a global view and control capabilities. The current and historical data from closed-loop operations is fed into AI&ML algorithms for knowledge generation and learning.
Centralized Learning and Routing paradigm
RL-based Routing. Our learning method for Network Mind uses reinforcement learning (RL), a framework for learning that controls rules based on experience and incentives. The Markov Decision Process is the basic idea of the in-used RL (MDP).
The goal of solving an MDP is to find an optimal policy that maps states to actions such that the cumulative reward is maximized, which is equivalent to finding the following Q-fixed points (Bellman equation):
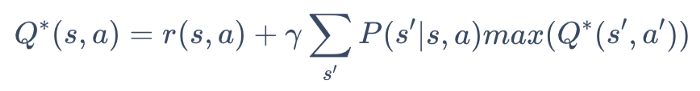
The first term on the right side represents the expected immediate reward of executing action a at s, and the second term is the maximum expected future reward. The discount factor models the fact that immediate reward is more valuable than future reward.
In the context of the learning routing strategy, each node can be considered as a state. For each neighbor s, there is a corresponding action a. Executing action a at s means forwarding the packet to the corresponding neighbor s.
The fixed Q-values of s can be regarded as its routing table, telling which neighbor to forward the data. This scheme is illustrated in Figure 4. With the help of this routing table, the optimal routing path can be trivially constructed by a sequence of table look-up operations. Thus the task of learning optimal routing strategy is equivalent to finding the Q-fixed points.
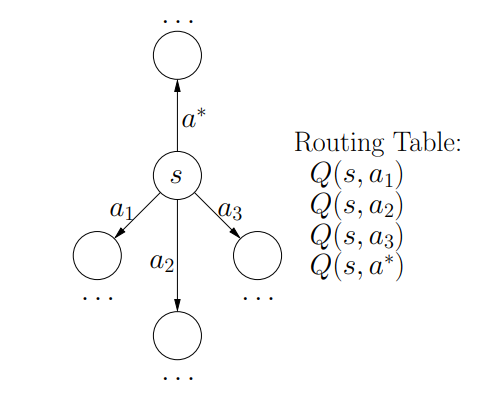
Figure 4: The routing table (Q-values) of a state s. The action a* with the maximum Q-value is selected.
Q-Learning. The Q-fixed points can be solved deterministically if the underlying transition model P and reward mechanism R are known. Q-learning is a temporal difference (TD) control technique that operates outside of policy and directly approximates the best action-value function.
When the agent acts a, they receive an immediate reward r from the environment. It then utilizes this reward and the predicted long-term reward to update the Q-values, impacting future action selection. In its most basic form, one-step Q-learning is defined as:
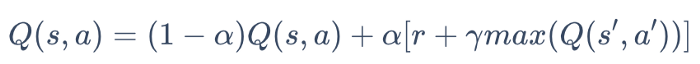
Where is the learning rate, which models the rate of updating Q-values.
AI Routers
Architecture
The hybrid AI-based hop-by-hop routing paradigm is introduced in Figure 5. We move the duty for intelligent control to the AI routers and use the network mind to promote global convergence in the design to reduce the overhead imposed by centralized control.
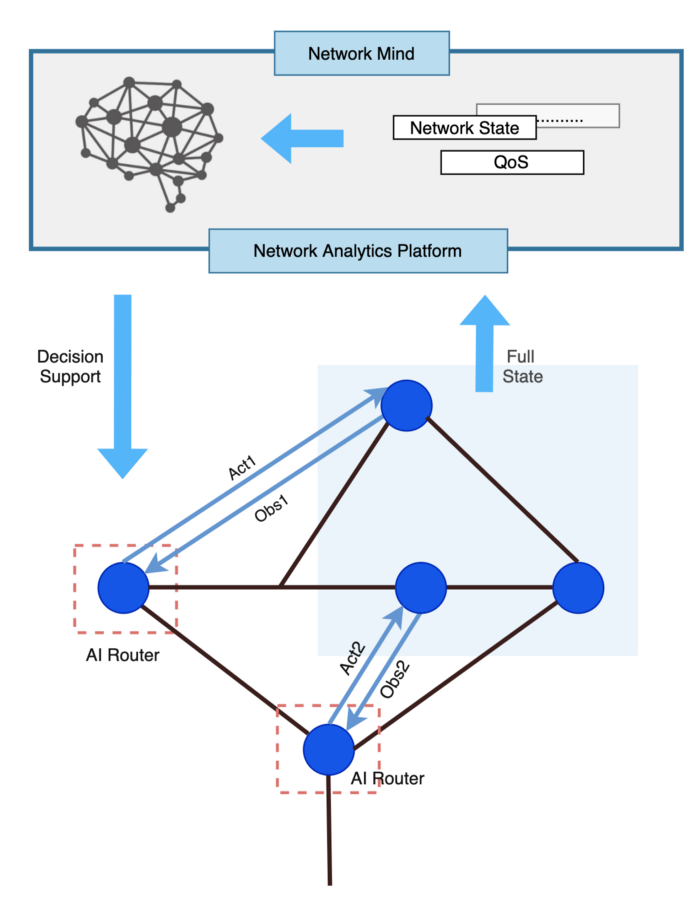
Figure 5: The decentralized intelligent control scheme
With the duty for intelligent control moved to each router, each router functions as an autonomous intelligent agent, and the dispersed AI agents form a Multi-Agent System (MAS).
Each AI agent maximizes the predicted cumulative reward by optimizing its local policy by interacting with its uncertain environment. In contrast to a single-agent system, where the activities of the single-agent entirely determine the environment’s state transitions, the state transitions of a MAS are determined by the combined actions of all actors.
The ability to exchange experiences across AI routers is critical for improving the overall value of this MAS. However, in this geo-distributed system, how to perform such information exchange is a crucial challenge for high-efficiency operations.
The centralized network mind is included in our design to act as a global knowledge convergence and experience exchange point. The centralized network mind may use the network monitoring system to obtain global network information and use the download connection to exchange knowledge.
Collaborative Reinforcement Learning
Collaborative Reinforcement Learning (CRL) is one of the most successful methods belonging to the Multiagent group, which algorithm is then described below. The CRL technique addresses system optimization issues in a MAS, which can be discretized into a collection of DOPs and described as absorbing MDPs in the following schema.

About the AIOZ Network
The AIOZ Network is a Layer-1 Blockchain-based Content Delivery Network that is about to bring a revolution to the entertainment industry.
AIOZ Network utilizes Blockchain for better content distribution by leveraging the power of decentralization. Unlike the traditional data centers operating on a centralized model. distributed Content Delivery Network (dCDN) uses Nodes for storing, streaming, and transferring data.
The AIOZ Network uses a faster, cheaper, and more robust infrastructure for content streaming making it more affordable, faster. This allows the AIOZ Network to provide a higher quality service.
By using this revolutionary technology, the AIOZ Network can efficiently change the way the world streams content of all sorts, improving the quality of life of many and shaping the re-evolution of information and knowledge for future generations.